As researchers and philosophers discuss the path towards human-equivalent / superhuman general artificial intelligence, they frequently examine the concept of control. Control of our world has always been of central importance to our species, so it’s no surprise that we’d look to extend our control in the future. However, most of the currently discussed control methods miss a crucial point about intelligence – specifically the fact that it is a fluid, emergent property, which does not lend itself to control in the ways we’re used to. These methods treat the problem as an algorithmic one, directly addressed with specific instructions that can be encoded to ensure proper behavior (harkening back to Asimov’s Three Laws of Robotics) – but the AI of tomorrow will not behave (or be controlled) like the computers of today. Emergent intelligence can’t be boxed up directly at an algorithmic level because this level is fluid, with constant shifts and changes that give the instructions no base to latch onto; the best we can hope for is to control it through a system of indirect rewards and punishments (much as we control human behavior today).
Before diving into the concepts of AI and control, it may be helpful to take a step back and align on the concept of emergence. An emergent property of an arrangement of objects is a property which could not be predicted based on the attributes of the objects themselves. This definition is a bit dense – so as an example, think of a river with a rock in the middle of it. For a common observer, with standard concepts of “river” and “rock”, the expectation would be that the water flows cleanly around the rock. However, upon further examination, they would find that the river + rock system results in whirlpools forming behind the rock as the water flows around it. In this example, the whirlpool is an emergent property of the river + rock system. This example highlights another key facet of emergence – it is dependent on the observer. In the situation just reviewed, the whirlpools being an emergent property depends on the observers limited concepts of “river” and “rock”; an experienced kayaker would expect the system to generate whirlpools (although they would lack predictive power of the type / size of whirlpool formed). We could even imagine a scientist that understands the system not as a river and rock, but as hundreds of trillions of individual molecules bumping into each other; as long as the scientist stays at this level of observation and explanation, very little is emergent (but also, very little is predictable) – emergence requires the use of limited concepts (which most human concepts are).
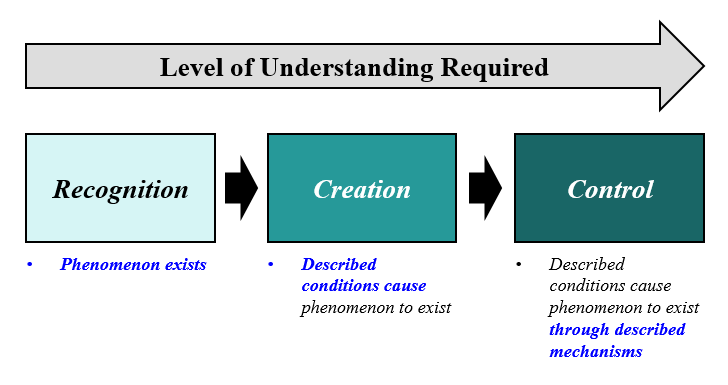
Let’s now extend the whirlpool example to take a look at how control and emergence play together. The first step in controlling something is to be able to create an instance of that something – so for this example, we need to understand what is required to create a whirlpool. Although whirlpools are emergent, it doesn’t take much to understand how to create them; after seeing a river with rocks in it, we quickly grasp the fact that it requires running water and an obstacle. In fact, we can create a new whirlpool simply by adding a rock to the river. Creation is only the first step in control, however; the more complete control we’re looking for requires influencing the actual behavior of the whirlpool. When we start trying to control the whirlpool’s behavior in this way, we realize this is a much more difficult problem than creation, as a variety of different factors (the size and shape of the rock, the speed and depth of the water, etc.) influence the behavior in complex ways. Creation is easy because we only need to understand the “initial conditions” required to form a whirlpool; we only need to supply the running water and the obstacle, and then let the laws of physics take it from there. To control the behavior, however, we actually need to understand the different ways in which these laws of physics come together to bring about the whirlpool (how the whirlpool “emerges” from them); we’d need to use mathematical models to figure out the structure required to drive specific types of behavior. Interestingly, the control problem is equally hard regardless of whether we seek total control (i.e. fully prescribing whirlpool behavior) or partial control (i.e. keep the whirlpool diameter at 3cm), as all parts of the behavior are interconnected, and so we’ll need to model complete behavior even if only seeking partial control (although there will be more “solutions” when seeking partial control). We can look to control behavior in other, more external ways (such as adding physical constraints in the water behind the rock), but the control offered by these methods will be inexact (unless we again construct a complete mathematical model of behavior, incorporating the constraints).
The whirlpool has served as a helpful example for highlighting the concepts of emergence and control, but it’s time for us to turn back to our main topic, intelligence. This prior post covers the nature of intelligence in more depth – here, we’ll focus just briefly on its emergent nature. The foundational element of intelligence in life on earth is the neuron, and the behavior of a single neuron is well described. The typical neuron has inputs (dendrites) and an output (axon), with the output being activated when the inputs reach a certain voltage level. Intelligence (and learning, wisdom, knowledge, emotion, feeling, etc.) is an emergent phenomenon when these neurons are arranged in a particular type of way (in conjunction with all the other structures required for a living organism). When arranged in the right way, these neurons are able to recognize patterns in the world and leverage these patterns to increase the organism’s chances of surviving and reproducing.
The crucial parallel between intelligence and the whirlpool is that, like for the whirlpool, controlling intelligence requires a greater degree of understanding than is necessary to create it. While we’re still quite far from any sort of general artificial intelligence, the first intelligences we do create will arise because we’ve figured out what “initial structure” is required for groups of neurons to recognize patterns and act intelligently. Crafting an “initial structure” in this way will not require a full understanding of how all parts of the brain work over time – it will only require a general understanding of the right way to connect neurons and how these connections are to be updated over time (much as we didn’t need a complete understanding of the laws of physics behind whirlpools to create them; we just needed to understand that a rock in a river would give rise to them). We won’t fully understand the mechanisms which drive this “initial structure” towards intelligence (think of how hard it is to understand even a whirlpool at this level!) and so we won’t have an ability to control these intelligences directly. We won’t be able to encode instructions like “do no harm to humans” as we won’t understand how the system represents these concepts (and moreover, the system’s representations of these concepts will be constantly changing, as must be the case for any system capable of learning!) The root of intelligence lies in its fluidity, but this same fluidity makes it impossible (or at least, computationally infeasible) to control with direct constraints. It’s much easier to understand the general neuron layout required for intelligence than it is to understand exactly how concepts are encoded in our brains and how those concepts change over time (which would be required for control). Luckily, we have significant experience as a species controlling intelligent systems indirectly – our robust system of law is a testament to this ability. We’ll need to rely on these same techniques when dealing with artificially intelligent systems, just as we do when dealing with other humans.
While we’re still very far from creating any sort of general artificial intelligence, we have made enough progress to see the emergent aspect of intelligence directly and to better understand the limitations associated with control. Before addressing this point further, it will be helpful to have an understanding of how machine learning (specifically image recognition) works today; this post provides additional details, but I’ll give a short summary here. Machine learning consists of simulating a large number of “neurons” with randomly weighted connections to each other, then using a large number of examples to “train” the system, with the initially randomized weights updated on each run to more accurately label the test images. For example, if training the system to recognize cats, you would show it thousands of pictures of both cats and non-cats (fed in as pixel values), with the system making a prediction on each image. After every batch of images, the connection weights are updated such that they system would have made more accurate predictions for the batch (the exact mathematics aren’t important here, but this is possible as the function of the total system is differentiable). Machine learning is powerful because it doesn’t require a programmer to understand anything about the features of the object that must be recognized – all the programmer needs is the algorithm and a vast number of training examples. When training a system to recognize a cat, the programmer doesn’t need to think at all about things like claws or fur or whiskers; instead, they think in terms of the general structure of the neuron system (i.e. 1000 neurons on layer 1, connected to 200 neurons on level 2, etc.) The programmer sets up the “initial conditions” (like the river and the rock), then lets the tendencies of the algorithm (like the laws of physics) run their course, creating a system which can recognize the desired image. Even once the system is “trained” and able to recognize the desired image, the programmer still has only a limited understanding of how the system does the recognizing – they can use certain techniques to understand the types of patterns recognized at each level of the system, but it’s extremely difficult to understand holistically what is happening; all the programmer knows is that the specific combination of neurons and connections now works to identify cats. This limited understanding means any sort of exact control of the system is off the table – for example, there’s no way for a programmer to structure the algorithm in a way so as to avoid identifying a certain type of cat. The programmer could force this type of cat not to be recognized using external methods (i.e. labeling images of that type of cat as “not a cat”), but there’s no way to disqualify a specific cat at the algorithmic level, as it’s not clear how that type of cat is represented. A deeper knowledge of the workings of the system would be required for this type of control to be exacted, and we’re quite far from having that level of knowledge even with the more simplistic AI programs of today. As we move towards more complex programs with generalized intelligence, the gap between creation and control will only widen, leaving us with intelligent programs at least as opaque to us as we are to each other.
Postscript
I thought of another, potentially more impactful, example of the difference between creation and control after publishing this article. In many science museums, you can find exhibits highlighting the nature of probability theory using a setup of balls and obstacles. A video does it much more justice than an explanation, so check it out here or here. This system can be thought of as driving the creation of a Gaussian distribution – to get the system going, you don’t need to understand exactly how all the bounces will go; you only need a general understanding that balls and obstacles are needed. Controlling this system, on the other hand, would require a detailed mathematical analysis of the possible bounce trajectories, and would be computationally infeasible. Creation is aided by the fact that, when things are set up a certain way, the system will tend towards a particular outcome; the system can be thought of as rolling down a slope towards the desired state. Control, on the other hand, requires understanding the slope of the hill, which is (generally) significantly more difficult to understand.
Author’s Note: If you enjoyed this post, please consider subscribing to be notified of new posts 🙂
“Emergent intelligence can’t be boxed up directly at an algorithmic level because this level is fluid” applying a broad generalization over what is possible with algorithms seems unjustified. have you examined every algorithm possible? ” the best we can hope for is to control it through a system of indirect rewards and punishment” seems a valid method for controlling AI very similar to our own minds, but the landscape of possible AI is vast. i imagine the possible AIs which are similar are but a tiny fraction of a fraction of ALL possible AI. furthermore, i see no valid reasoning… Read more »
[…] chess than to figure out which neuronal connections are needed for chess abilities from the start (a bit more on this idea here). We will run into a similar situation with general AI systems; the more generality we seek, the […]
[…] intelligence doesn’t “play well” with this type of control (as discussed more extensively in Emergence and Control). By this, I mean that it is far easier to construct a generally intelligent system than it is to […]