In his book I am a Strange Loop, Douglas Hofstadter paints a powerful analogy involving the careenium, symms, and symmballs. I highly recommend reading the book (as well as all his other works, if you have the time), but I’ll summarize the analogy briefly to start, as this post involves extending it to help drive our intuitions about AI.
In Hofstadter’s scenario, the careenium is a billiard table, with a vast number of small, magnetic balls (symms) randomly bouncing (careening) around it. These symms interact with each other, forming clumps of various sizes, coming together and breaking apart as the substrate of symms buzzes around the table. If you zoom out, you can see that there’s a certain degree of regularity to this clumping, with particular types of structures coming together – Hofstadter calls these higher-level formations “symmballs”. Crucially, the edge of the careenium changes its “bounciness” depending on the state of the world outside it, and in this manner “passes” the information to the symms. From the zoomed out view, you can see that the behavior of the symmballs is complex; they appear to mirror the outside world in certain ways while also interacting amongst themselves (in an extended version, to drive behavior in the outside world).

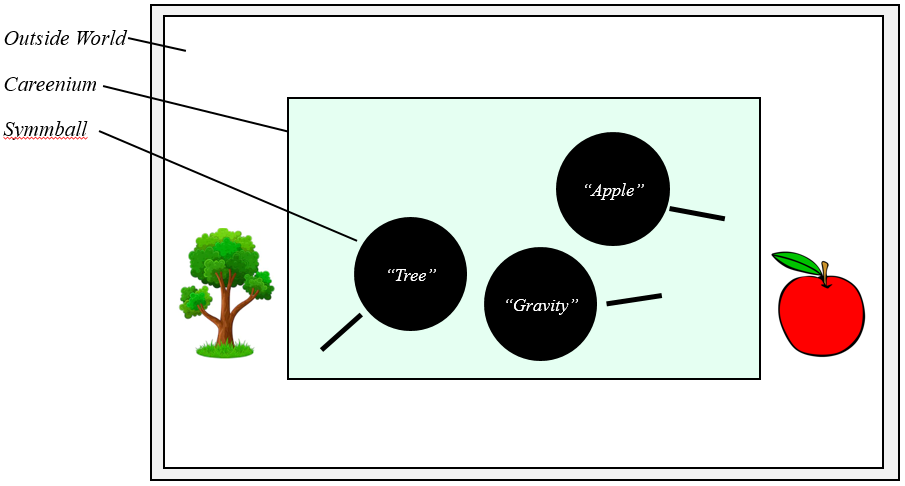
With the full picture sketched out, Hofstadter then asks, “who pushes who around inside the careenium?” From one perspective, the symms are doing the pushing, as the whole system can be viewed as symms bumping into other symms. However, from another perspective, the symmballs are doing the pushing – as symmballs dance with other symmballs in a coherent, representative way. As you may have guessed from the naming conventions, Hofstadter maps this scenario to the brain; the careenium is the cranium, the symms are the neural substrate, and the symmballs are symbols (i.e. concepts). Just as the processes of the careenium could be viewed two ways, so can the processes of the cranium, with individual neurons and action potentials at one level and neural representations (symbols) at another.
Hofstadter extends this analogy further to look at our sense of “I” and where this sits (as a symbol representing the system itself), but that part is less important for using the analogy to further intuitions about AI. The important part is that we can think of the brain as a system made of symms, with the particular rules which govern simm interaction, resulting in a system that tends to capture and exploit the regularities of the world.
Before proceeding to AI intuitions, we’ll need to extend Hofstadter’s analogy in two ways. First, we’d like to capture the fact that the brain learns (and changes) over time. One way of thinking about this learning process in the careenium might be that, when simms hit each other or the careenium, their level of magnetism changes slightly. Over time, these changes in magnetism result in the symms forming symmballs which are better representations of the outside world. Additionally, we’d like some way of capturing the innate motivations which brains have (separate from any internal model of the world). We can extend the analogy a bit and consider that the shape of the careenium may influence the formation of symmballs, making some types more easily formed than others (desire for power / spirituality vs. paperclip maximizing).
We’ve now built out a somewhat complex analogy (as shown below), but hopefully one which draws the essence of our general intelligence into greater focus. We have the symms, careening around the careenium (which is shaped a certain way); they bump together with other symms and against the walls of the careenium, updating their magnetism and incorporating inputs from the outside world (the “bounciness” of the walls). Their motion is such that, from a zoomed out view, they form symmballs, which represent certain regularities of the outside world (as well as possible actions, etc.) and dance together to form other symmballs, ad infinitum. This system is general because, although the careenium has a shape, it does not fully constrain the behavior of the symms; the symms are free to “apply” their algorithm to any inputs from the careenium and make sense of them.

Now that we have that analogy together, let’s map it onto standard AI systems. We can start from the top, where we have a specific model. That model has a specific objective function, which we can view as analogous to the careenium’s shape, as it guides the behavior of the underlying substrate. One key difference, however, is that the objective function fully constrains the system’s behavior, whereas in the careenium (and the brain), the shape serves as more of a general guide (e.g. we can choose to ignore hunger, but an AI system structured to win at Go can only move in the direction of improved Go ability). This constraint impacts the symmball level as well, as the only types of concepts which the AI system can form are those related to its objective function. There’s no general world modeling going on, only goal seeking. The root cause of this can be seen at the level of the nodes and connection weights. In the careenium, the symms updated their routes and magnetisms based on interactions with each other and the walls (outside inputs) in such a way as to “capture” and “make sense of” the inputs. In our AI system, however, the updates happen in such a way as to “move closer to goal achievement” – some “capturing” and “making sense of” can happen as a side effect (when it helps achieve the goal), but it is not the target. This is because the update algorithm is directly linked to the objective function; the behavior of the system tends towards “(narrow) goal accomplishing”, rather than “world representing”.

Hopefully the previous example helped drive some intuitions about the limitations of AI as commonly structured. The limitation stems from the rigidity of its “shape” (objective function); because its update process is directly tied to this rigid shape, it is constrained in the types of “concepts” it can form (only those directly related to the goal). While this method of AI development has limitations, our species is also constrained in our ability to apply other methods. Our brains (and potentially, thinking machines in general) generally use a top-down approach to understand the world, making it difficult to come up with the bottom-up algorithms needed to generate the desired types of behaviors. For those familiar with Conway’s Game of Life or cellular automata, the problem is akin to (though much more difficult than) coming up with a set of cell update rules which will generate a certain type of behavior. Without actually running simulations, it’s extremely difficult for our mind to understand likely outcomes / generalize, as the high level behavior emerges from the low level rules. That being said, we do have one powerful example of a more bottom-up type AI system, which may help us think differently about how to build systems in the future.
GPT-3 is a natural language model constructed by Open AI which has been able to achieve a number of impressive results, including convincingly writing poetry, creating news articles, and acting as a dungeon master. The model was created using an objective function of predicting the next word in a sequence of text, with training conducted over ~45TB of data from various sources. At first glance, this seems to be another instance of a standard AI model, with a rigid shape and limited concepts (and to some degree, it is) – however, looking more closely at the objective function, we can see that it’s significantly more general than others we’ve considered. Aiming the system at a general goal (predict the next word), results in an update algorithm that comes significantly closer to “modeling the world”. We can imagine extending the GPT architecture even further, where instead of words as input, we use a video and audio feed, and give the system an objective function of predicting the next frame / frequency. When viewed this way, we can see that, for this type of system, the objective function doesn’t impose a rigid shape; rather, it serves to drive a low level, “world modeling” update algorithm. This general update algorithm can form whatever types of “concepts” are useful for understanding the world, as it’s not constrained by an objective function – or, viewed slightly differently, its objective function requires it to form concepts corresponding with the world (rather than to any narrow goal). The key intuition which GPT-3 provides is that to achieve generality we need to build systems where the behavior we want (e.g. writing poetry) emerges from the lower level objective function (predict the next word). We need to focus on specifying how the symms move and update, not on what types of symmballs we want to see formed or what types of (narrow) objective functions we’d like to see solved. Additionally, we need to focus on what type of “shape” to give these systems; for when we do figure out the right “world modeling” algorithms, we’ll need to make sure we give them the right “drives” (as they may quickly become quite competent).
Author’s Note: If you enjoyed this post, please consider subscribing to be notified of new posts 🙂