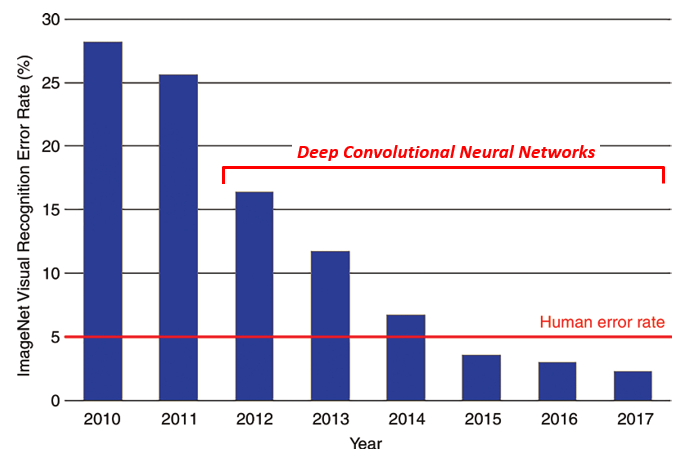
The field of machine vision has progressed rapidly over the last decade, with many systems now achieving “better than human” results on standardized image recognition tests. Deep convolutional neural networks have been a main driver of these improvements, and have been enabled by increasing data availability and computing power.
ImageNet Competition Best Error Rate Performance, 2010 – 2017
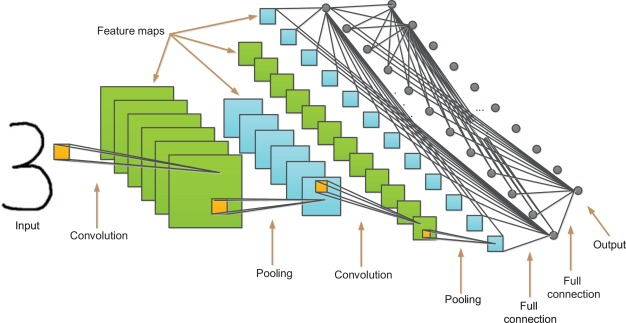
At a high level, these systems work by setting up a number of layers of nodes, or “neurons”, with the nodes of each layer connected to those of the layer above and below (the “deep” in the name refers to the fact that there’s more than one layer). Each of these connections has a weight, and to start these weights are randomly initialized (resulting in random outputs). The weights are then updated during training to move closer to values which do better on the training examples (this is done using an algorithm called backpropagation). All deep neural networks have these attributes, and convolutional networks are a special type which apply their operations across all parts of an image, making them shift-invariant. For those less familiar with how these systems work, this post provides a more rigorous explanation (and the image below, from here, provides a visual).
For all the advances this approach has driven, it seems (at least as currently structured) to have a core issue; neural networks, when learning to recognize objects, “see” things very differently than humans do, and are easily tricked by examples which would never fool a human (interestingly, the initial pathways of the human visual system do share some commonalities with deep convolutional neural networks; the later processing in the cortex is where the differences arise). For example, take a look at the two pictures below (from this paper):

Presumably, you see two fairly identical pictures of a panda. GoogLeNet (a neural network image identifier created by Google) would agree with you on the left picture, but would label the picture on the right a gibbon. It would do so because the right picture was intentionally doctored, adding small amounts of noise to the image to just the right pixels to drive up the “gibbon” activation and drive down the “panda” activation (see below).

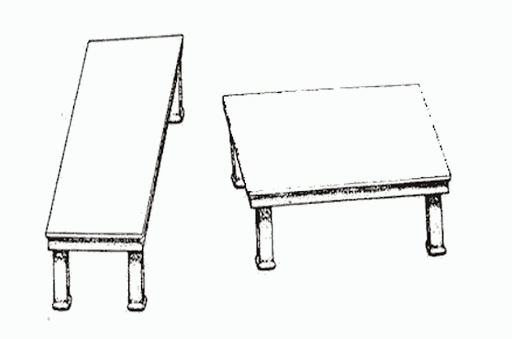
This doctoring process is robust, and has been shown to be possible on a wide variety of neural networks and types of training examples. There seem to be a few reasons for this deficiency in performance vs. the brain (at least, a few that come to mind immediately – I’m sure there are many others). For one, neural networks lack the ability to incorporate context like we do, as they’re trained on specific examples, and are exactly tuned for them (essentially, they only have the concept “panda”, and can only “search” for that specific pattern, whereas we leverage our concepts of “tree” and “sky” to make sense of the image – though if “tree” or “sky” patterns show up in most panda pictures, the network can incorporate those patterns as part of its “panda” concept). Additionally, these networks lack the top-down feedback pressures of the brain which help us to fit sensory data into a sensible worldview; the bottom-up calculations of the neural network simply output a value, with none of the “consistency checks” our brains perform (these top-down pressures are responsible for many optical illusions, as our sense of how the world should be supersedes the actual sensory data; for example, the below tables are the same size, but our understanding of how tables exist in the world forces us to see them a particular way).
The deficiencies just described are important to consider and deserve further exploration, but that will be left for a separate post; this post will be addressing a different issue, which is that of insufficient sparseness of concepts.
Before diving into this deficiency of neural networks, it may be helpful to first take a look at how humans recognize objects. At birth, babies aren’t capable of recognizing any particular objects, but they do seem to be able to recognize that objects exist (in the broad sense, i.e. that particular clumps of matter are distinct from other clumps). There seems to be an innate “object recognition” ability built into us by evolution, and over time, as we’re exposed to the actual objects of the world, we form conceptions of those particular objects / patterns which tend to manifest themselves. We can think about these object conceptions as being built “from the ground up”, with the innate “object recognition” serving as the base, and particular instances of object conceptions being built up from there (based on the examples we observe). Thinking more abstractly, we can even envision the space of possible objects (or really, possible sensory observations) as a 2D surface (the “object-space”). In the real world, certain areas of this object-space manifest themselves more often than others; for example, the panda-like and gibbon-like areas both occur fairly frequently, while the “half panda-like half gibbon-like” area does not naturally occur. Taking advantage of these regularities, humans have covered / grouped together particular areas of the object-space with concepts (e.g. panda and gibbon). This view of concepts and how humans come up with them is explored more fully here.

In reality, the object-space would be best represented by a large number of dimensions; while this is harder to visualize, in this multi-dimensional space we can imagine even more sparse “concept islands” forming, with significant gaps (in most dimensions) between distinct concepts. While this description is directional and abstract, the key takeaway is that human concepts are built from the ground up, based on observed object instances, meaning that there’s generally plenty of space between specific conceptions (i.e. the concept-space is sparse). In the gaps lie patterns of matter which don’t exist in our world.
While humans build up concepts from examples, neural networks function a bit differently. Rather than starting with a base conception of “object”, these systems begin with the entire object-space covered by particular labels, in a random fashion. This means that, to start, the panda image and the noise image have an equal chance of being recognized as pandas (or gibbons, or bears, etc.) – the entire space is covered by the system’s labels.
As the system moves through the training process, the weights (and the resulting concept coverage) gets pulled in the direction of the correct labels, resulting in concepts which perform better on the test data.
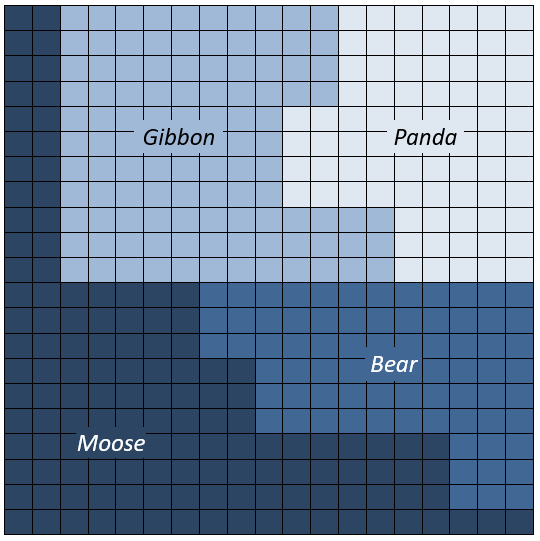
At the end of this process, we end up with a system that generally performs well in the domain it’s tested in, but that has broader conceptions than humans which are less directly tied to the actual regularities of the world. The above image provides an idea of what the system’s object-space coverage might look like in two dimensions, though the actual multi-dimensional nature of the space means there are many more ways for the neural net’s concepts to deviate from humans. As we saw with the panda example, it only takes small (albeit intentional) tweaks to arrive at an area of disagreement due to the lack of gaps in the system’s coverage.
A human creates panda and gibbon concepts through repeated observation of two particular patterns of matter, with the large gap in between reflecting the non-existence of “half panda-like half gibbon-like” patterns of matter. If you start with a picture of a panda and gradually change it to look more like a gibbon, a human will call it out as not realistic long before they call it a gibbon. Deep convolutional neural networks, on the other hand, lack this “not realistic” gap between concepts, and their gibbon concept runs right up to their panda concept. Though the “center” of their concepts may be close to “centers” of the human concepts in the object-space, their overall boundaries vary a great deal, as they are the result of pulling the random initial coverage into place based on examples, rather than on constructing a concept from the ground up. Put more simply, their coverage of the object-space is too dense.
This issue does not seem to have an easy solution within the existing framework of deep convolutional neural networks. Humans had the advantage of 500 million years of neural evolution to craft a method of sparse concept formation, and this method may not be straightforward to replicate. Most machine learning methods are reliant on the practice of random initialization followed by updates based on training data, whereas for humans the initialization is far from random (and the update process is likely more complex than a single algorithm like backpropagation, and the structure of the system is more complex than homogeneous nodes / connections). Looking at a theory of brain functionality like predictive coding / predictive processing, we can see how far we may still have to go; while we’ve figured out a way to coherently process sensory input, we still need to clear the larger hurdle of putting together sparse conceptions in a way that enables top-down prediction of the world.
P.S. While not directly related to the abstract view of concepts discussed here, this article by Subutai Ahmad and Jeff Hawkins provides a more mathematical view of the advantages of sparsity and what it might mean for neural representations. An interesting read, and one that further highlights the power of sparsity!
Interesting stuff, thanks for the detailed explanation! Do you have thoughts on how things could change to better support the top-down prediction you were mentioning?
Glad you enjoyed it! That’s the billion dollar question 🙂 I think right now our best bet is likely to look toward the brain for understanding; though we have a fairly solid understanding of its low level mechanisms, it seems we’re only at the beginning of developing a higher level computational understanding. One piece I think will be especially important for this computational view is the role of feedback inhibitory connections. It seems these could help drive that top-down influence, ensuring consistency by controlling which clusters of neurons can fire together. These types of connections don’t fit as cleanly into… Read more »
Thanks for this. Do you think the doctoring process used to trick the neural network into thinking the panda was a gibbon could conversely, actually be used to train them to identify objects on a more ‘human’ level? It likely wouldn’t be able to give them context, but could it help them identify objects on a less binary basis?
I think that’s a great idea – in fact, it was actually explored in section 6 of this paper and found to help the network better generalize! This makes sense to me at a high level; essentially, you’re finding the “gaps” in the model’s understanding, and then putting it through training to fix those gaps. Due to the complexity / multidimensionality of the “object-space”, it seems there may be limits to how much upside you could derive from this technique (in the simpler domain of MNIST referenced in the paper, the model improved from a ~90% error on adversarial examples… Read more »