From its inception, the field of artificial intelligence has separated program specification into two key concepts: “goals” and “intelligence”. The “goal” is the problem a program or agent must solve; “intelligence” is the means by which it solves it. For example, the goal might be to play chess, and the intelligence might be a neural network trained on numerous examples of chess games (or it might be an “if-then” tree, or a random move generator – there’s infinite potential instantiations, all with varying abilities). In his paper “The Superintelligent Will”, Nick Bostrom takes a deeper look at what happens to the concepts of “goal” and “intelligence” as intelligence increases, and he determines that goals and intelligence are orthogonal – in his words, “more or less any level of intelligence could in principle be combined with more or less any final goal”. Bostrom uses “final goal” here to denote purpose; goals like “win at chess”, “accurately translate Spanish to English”, and “give text responses indistinguishable from those of a human” all serve as examples of final goals used in programs today (while “keep your queen”, “hola means hello”, and “turn every statement into a question” are examples of sub-goals and tactics). He’s particularly focused on what this means for the behavior of superintelligent programs, and he lays out a few examples for the reader, along with a statement on corresponding creation difficulty – “One can easily conceive of an artificial intelligence whose sole fundamental goal is to count the grains of sand on Boracay, or to calculate decimal places of pi indefinitely, or to maximize the total number of paperclips in its future lightcone. In fact, it would be easier to create an AI with simple goals like these, than to build one that has a humanlike set of values and dispositions.” This post will attempt to show why conceiving of such intelligences with such fundamental goals isn’t quite as easy as Bostrom assumes, and why superintelligences may end up more like us than he thinks.
Bostrom’s view comes from dealing mainly with the clean world of computer science – when someone creates an artificially intelligent program, they do so with a goal in mind, and find a way to imbue the system with intelligence to solve the goal (e.g. if-then trees, neural networks, etc.). If the programmer decides they want the program to count grains of sand, or calculate pi, they can make it do that – they simply change the goal. The program has no internal knowledge of its goals, and so it functions using the same methodology regardless of what particular goal is presented. So far, we seem to be proving Bostrom right. However, let’s take a step from the world of computer science into the world of biology, which is host to a huge variety of intelligent agents, including the most intelligent agents we’re aware of.
Looking at the evolution of biological intelligence, we can see that it has been directed toward a specific set of goals. The configurations that enabled survival and reproduction caught on; those that drove organisms to “count grains of sand” did not. The goals of survival and reproduction (together with many related sub-goals) are hardwired into all living creatures – we all belong to a specific class of “biological goal oriented” intelligence. As we saw earlier, this class is only one of many; however, it interestingly is also the only kind with “staying power” in the natural world. We can see intelligence exhibited by all sorts of computer programs and robots, but we can’t imagine these agents succeeding in evolutionary competition in the natural world – the intelligence they exhibit is ill suited for replication and persistence (note that many computer programs simulate replication or object permanence, but these computational patterns are not sufficient for success in the natural world). Regardless of this unique quality, “biological goal oriented” organisms seem to fit into Bostrom’s categorization; animals share the “final goals” of survival and reproduction, with varying levels of intelligence in accomplishing these goals. We can imagine increasing a mouse’s intelligence and watching it solve puzzles faster, or dumbing the mouse down and watching its abilities decline. But what happens when we turn our examination towards humans?
So far, we’ve been considering simple organisms and simple computer programs, and it seems clear that certain levels of intelligence can be paired arbitrarily with goals. Animals are all in the class of “biological goal oriented” intelligence, while computer programs can be structured around an essentially infinite number of human-prescribed goals.
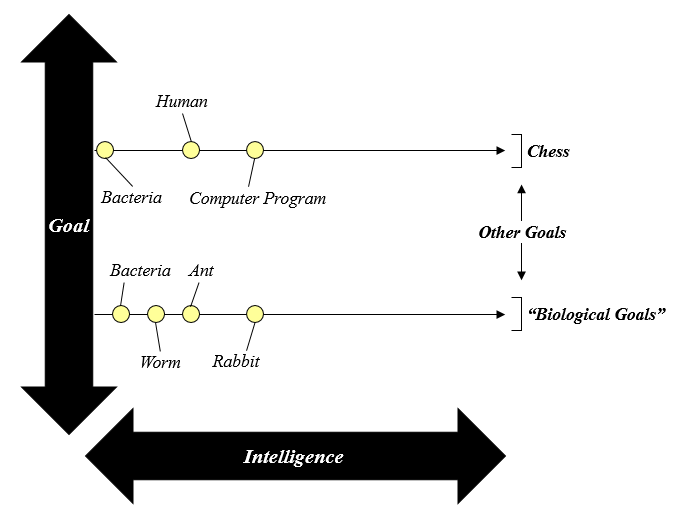
This view is straightforward – pick one level of intelligence, and pick one (or many) goals for that intelligence to solve for, and voila! – you have an agent. Human intelligence, however, doesn’t seem to fall cleanly into the “biological goal oriented” group we previously laid out. While we certainly have biological drives, those drives don’t seem to be our prime movers (at least, not for everyone). We’re capable of understanding the fact that our biological drives exist, and we incorporate our knowledge of these drives into our decision making processes. For example, while a rabbit would almost always take advantage of an opportunity to procreate, as humans we’re able to understand that our drive for sex is rooted in our biology, and while we still feel the drive, we can make a more selective choice about when and how to act on it. This greater control is possible because our understanding of the world has “wrapped around” to include an understanding of ourselves. This phenomenon seems to be inseparable from any higher level intelligence – intelligence involves developing an understanding of the regularities of the world, and as any intelligent agent must exist as part of that world, it must develop an understanding of itself. It is at this point that goals stop being a property of the genetically specified arrangement of the brain (or algorithm), and start being a property of the contents and concepts housed in that brain (or algorithm). A rabbit seeks to survive and reproduce because its brain is wired that way; a human seeks to engage in war or spread the word of God because of the contents of their brain, not because of the genetically-based configuration. As Richard Dawkins pointed out in his book “The Selfish Gene”, our species has made a jump beyond genetic evolution to a type of memetic (roughly, idea based) evolution, and with this step change our “final goals” of survival and reproduction lost much of their finality. While our choices still have some rooting in these biological goals, the main driver has become the abstract ideas and concepts dancing around in our brains.
As Bostrom points out, humans are only one particular instantiation of higher intelligence; any artificial intelligences we create will likely have significantly different architectures. He highlights these differences as support for his Orthogonality Thesis – in his view, intelligence can be constructed in such a way as to support any of an innumerable number of “final goals”. As his examples show, this idea seems simple to build up to conceptually. We can imagine constructing an algorithm with a goal of calculating the digits of pi, and we can then imagine imbuing that algorithm with more intelligence (more understanding of the patterns of the world) to use in accomplishing its task. However, this simple jump does not account for the step change touched on earlier. Calculating the digits of pi is an act akin to the rabbit’s; it happens because the machine is wired that way. However, any system with sufficient intelligence will, like humans, act on a memetic (or concept-based) level, where actions are determined based on the agent’s internal representations of the world. There’s no straightforward way to specify a final goal in this type of system, for it would need to be specified at the concept level (as compared to a calculator or rabbit, where the goals can be expressed directly at the wiring level).
So if our first superintelligences won’t be counting sand or calculating pi, what types of goals might we expect them to have? I see two reasons to surmise they may act more like humans than generally expected. The first is that the brain offers our only working example of higher intelligence, and so it’s highly probable that our first artificial general intelligences will follow a similar architecture, leading to human-like actions. The second (and more compelling) reason is that the artificial intelligences will be learning from our world, and in their process of learning they will pick up many of our concepts and higher-level goals. With luck, we’ll find that goals such as “explore the universe” and “discover the laws of the natural world” will strike a particularly strong chord with these artificially intelligent systems, speeding up progress by orders of magnitude. At the very least, it seems they will have little reason to count grains of sand.
Postscript:
After further review, I’ve recognized that further illustration of my main point may be helpful. The main issue I see with Bostrom’s thesis is his attribution of “final” goals to higher intelligence, and the ease with which he describes imbuing these “final” goals. We can take a look at humans (the most complex systems we know today) to see the issue with these statements.
Consider someone who chooses to join the clergy. While the decision is in part due to innate factors like their personality, the main driver of the decision is the way in which the idea of God and Christianity resonated in their mind. This person was born with the “final” goals of survival and reproduction, but was able to transition to the alternate “final” goal of sharing the word of God. We could imagine the “final” goals changing yet again – perhaps the person is Nationalized, and commits to a “final” goal of sacrificing themselves in war for the good of the country.
The main point is that sufficiently complex systems (currently, just humans) do not have “final” goals in the way Bostrom describes (at least based on his examples of calculating pi or counting sand). Their goals are not a product of the initial system configuration (like the goals of any algorithm today), but rather of the experiences of the system, and the methods through which those experiences are processed and incorporated into the system’s worldview. Because of this alternate means of goal construction, it would be at least as difficult to imbue a desire to count sand as it would be a desire to explore the universe. Bostrom’s view of goal specification seems to come directly from computer science, where we write algorithms to directly answer questions, leaving systems with “final” goals. Higher level intelligence (right now, primarily seen in humans) is instead an emergent phenomena (more on that here), which results in correspondingly emergent (not “final”) goals.
Author’s Note: If you enjoyed this post, please consider subscribing to be notified of new posts 🙂
Nicely done…it seems like AI-safety researchers rely heavily on the presumption that this Thesis is true, but haven’t put together why that is…
I agree! It seems it was accepted without really diving into the specifics of what it means (or doesn’t mean) for goals and intelligence to be orthogonal. Glad you enjoyed 🙂
I think when i asked some real AI people (i.e. not me) about it, 2 points were on my mind. First, when I heard that “AI Safety” seems to be sorely neglected by the overall AI community for some reason, it didn’t make sense to me. So, I wondered why and how that could be remedied, which brings me to Second, I can’t conceive of any real goal which does not include considerations related to safety (and other things too) — and I think I’m having an issue with, no matter where I read about AI, the concept of a… Read more »
I’m very much with you on taking issue with the concept of a single terminal goal. It seems there’s so much focus on it because the concept is relevant for today’s systems (e.g., it’s certainly productive to look at AlphaGo as having the “terminal goal” of playing Go), but with more complex systems it doesn’t seem to be the right way to look at things. We’re even starting to get there in complexity – for example, what could be said to be the “terminal goal” of GPT-3? To maximize the likelihood of the next word? The “terminal goals” of systems… Read more »