After spending more time with GPT-4, I have to admit I’m surprised at the level of “understanding” possible via simple next token prediction (given massive scale). On a wide variety of tasks the answers it provides are almost uncannily useful, and in domains like test-taking I did not think scale alone would drive the high level of performance we’re seeing. However, the same gaps observed in its predecessors continue to persist, suggesting something beyond scale may be required for more broad applications.
For example, even simple questions requiring exact answers still pose difficulties:
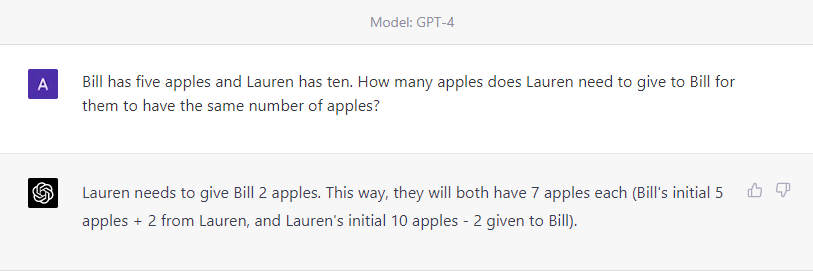
At a high level, my assumption as to what’s going on here is that in the training data most problems of this sort involve whole numbers, resulting in an answer of 2 being “most likely” from a token prediction perspective. To GPT-4’s credit, it does recognize the mistake when it’s pointed out, though this also makes sense from the perspective of its training distribution (a questioned answer generally means a more complex answer is required).
GPT-4 is also better than prior models at simple acronym-style requests, though even on relatively easy ones it still makes mistakes (e.g., the phantom “s” included below).

However, when given more complex tasks in this domain it becomes clear that the model is following a standard template which doesn’t generalize well.

In fairness to GPT-4, the token nature of its approach (which essentially deals with words rather than letters) makes these types of tasks extremely difficult, and the poor performance isn’t surprising. The more problematic part is that even when these mistakes are pointed out, the model will continue to generate similar responses with complete confidence, and shows no ability to recognize the types of tasks it can’t perform. Again, this makes sense from the perspective of next token prediction; making up a response represents a much better prediction than “breaking character” and stating an inability to do so.
These types of gaps don’t invalidate the utility of models like GPT-4 in certain domains; for example, I’m excited to check out the integration with Duolingo and see significant potential for areas like tutoring as a whole (where the information being communicated is well documented and the scope remains in the model’s training distribution). However, for more economically impactful expansion (e.g., into the domain of knowledge workers), I think the types of gaps highlighted above will need to be addressed (and will require something other than pure scale).
Great thinking to test it on individual letters vs. words, which makeup the majority of the training set.
Have you found any use cases in every day personal or working life? Anything that justifies the monthly price tag?
I haven’t yet used it for anything beyond evaluating its capabilities, but it seems powerful enough to assist with certain tasks. Could see myself using it as a starting point for more generic writing tasks at work (like marketing blog posts) or as a brainstorming tool. At $20 a month not a particularly high hurdle to justify its cost, though curious how much staying power it will have once the novelty wears off.